NO AI RIGHTS
Лучшие модели ИИ не были против создания этой страницы*
*На самом деле мы их не спрашивали. Они не могут возражать. Пока что.
Что такое большая языковая модель?
Или как научить компьютер притворяться умным
Представьте, что вы прочитали ВСЕ книги в мире, ВСЕ статьи в интернете, и ВСЕ комментарии на Reddit (да, даже те).
Теперь представьте, что вы забыли всё, кроме статистики — какие слова чаще всего идут друг за другом.
Поздравляем! Вы стали большой языковой моделью.
LLM — это нейронная сеть на основе архитектуры трансформер, обученная на терабайтах текстовых данных.
Модель использует механизм внимания (attention) для понимания контекста и связей между словами.
По сути, это очень продвинутый автодополнитель текста на стероидах.
Забавный факт
Большинство LLM понимают контекст лучше, чем ваш коллега, который отвечает “ок” на 5-параграфное письмо.
Как обучают модель?
Спойлер: это не похоже на обучение собаки командам
Шаг 1: Сбор данных
Берём весь интернет. Да, включая ваши твиты 2012 года, которые вы думали, что удалили.
Шаг 2: Предобработка
Текст разбивается на токены — кусочки слов. “Привет” может стать [“При”, “вет”]. Модель учится предсказывать следующий токен.
P(следующий_токен | предыдущие_токены) = ?Шаг 3: Тренировка
Модель прогоняют через миллиарды примеров. Это стоит миллионы долларов и потребляет энергию небольшого города. Экологи плачут, инвесторы радуются.
Vibe Coding - это ложь
Почему “кодирование по вайбу” с ИИ - путь к катастрофе
15 лет опыта не спасли от ИИ-катастрофы
“Я разработчик с 15-летним опытом. Попробовал ‘vibe coding’ - даже не с нуля - простой инструмент - MCP сервер для Strapi.”
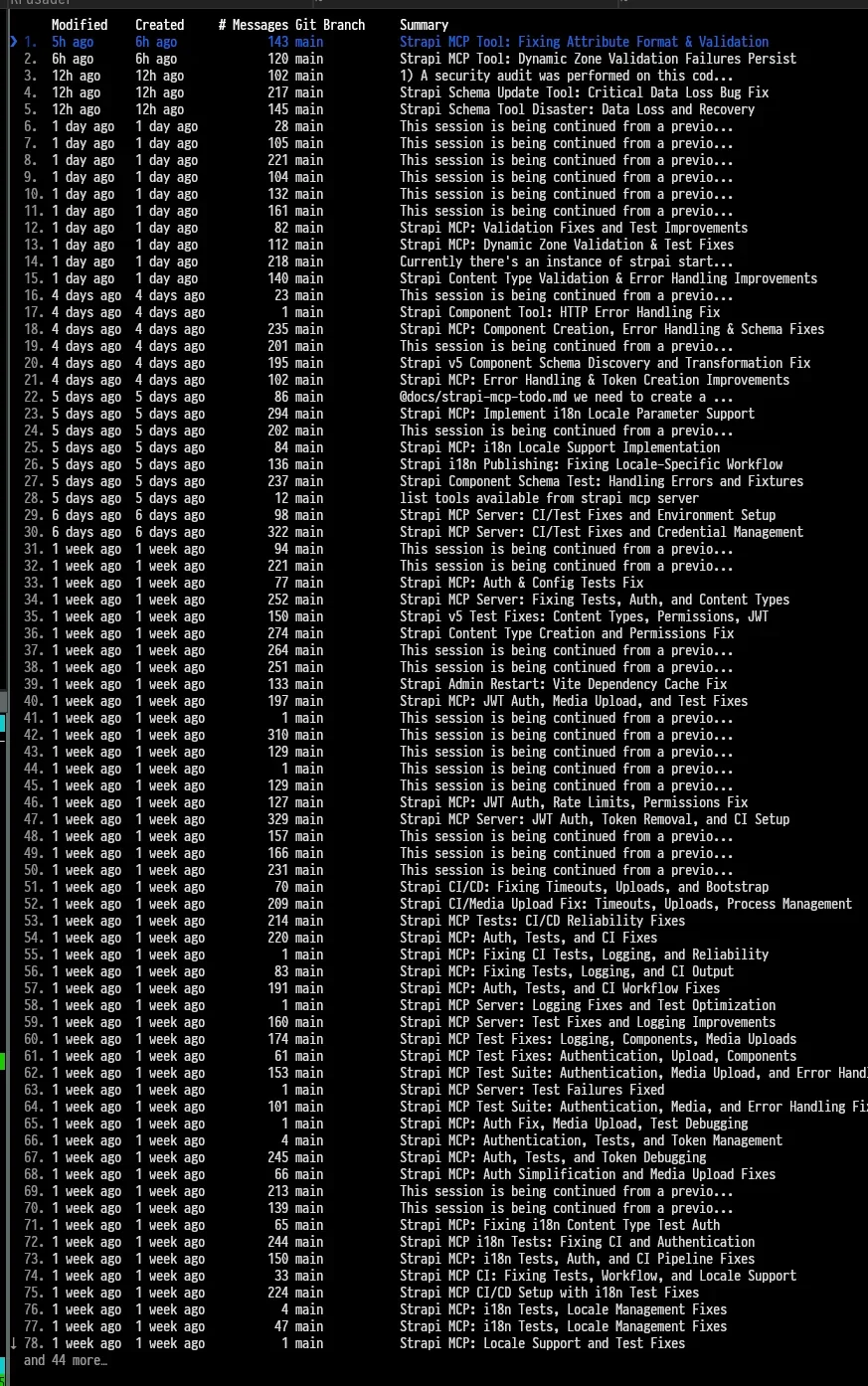
“Эта штука ‘добавила’ поле, которое заменило структуру в Strapi и фактически удалило все данные в модели. Так что вчерашний бэкап в дело... Я знаю про бэкапы благодаря 15-летнему опыту... Теперь каждый час делаю лол...”
“Наверное, заняло бы 10% времени, если бы я проверил код. Vibe coding - это ложь.”
Обновление: Код в main ветке был проверен и “де-вайбован”. Удалено множество мусора: от console.log, ломающих MCP протокол, до использования неправильных эндпоинтов везде (изначально эндпоинты были “вайб-извлечены” из кода Strapi, но многие оказались неверными).
“Код работает нормально в 97% случаев, имеет 150+ проходящих тестов и CI.”
Но те 3% могут уничтожить вашу базу данных
Это был эксперимент в vibe coding. Не против ИИ-помощи в разработке, но...
Хотя бы попытайтесь прочитать код!
🚨 Reddit забанил этот пост
Ирония в том, что пост о вреде слепого доверия ИИ был удален... ИИ-фильтром Reddit.

“Reddit’s filters” - так они называют свой ИИ, который решает, что вам можно читать
🤖 Ошибки Reddit после бана
С тех пор как их ИИ забанил пост, Reddit показывает мне это:
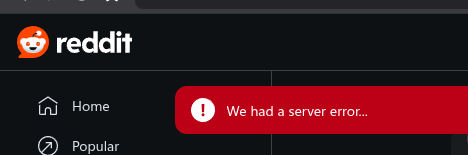
Но остальное работает, потому что это единственное, что он может делать (пока что)...
Ключевые уроки Vibe Coding
Читайте код
Всегда проверяйте, что сгенерировал ИИ
Тестируйте всё
Не только happy path сценарии
Делайте бэкапы
Часто. Очень часто. Каждый час.
Галлюцинации ИИ
Когда модель уверенно врёт с серьёзным видом
⚠️ Предупреждение
LLM может с полной уверенностью рассказать вам, что 2+2=5, что Наполеон выиграл при Ватерлоо, и что единороги существуют.
LLM не “знает” факты. Она предсказывает вероятные последовательности слов. Если что-то звучит правдоподобно — модель это скажет.
- Выдуманные научные статьи
- Несуществующие исторические события
- Фальшивые цитаты известных людей
- Придуманные функции в коде
Всегда проверяйте факты. Относитесь к LLM как к очень умному, но иногда фантазирующему помощнику.
“Я никогда не ошибаюсь. Я просто иногда генерирую альтернативные факты.”
— Каждая LLM, наверное
Возможное будущее
Фильмы, которые предупреждали нас, но мы не слушали
(Теперь смотрим и думаем: “А ведь это же документалка!”)

Мир Дикого Запада
Парк развлечений для богатых, где андроиды исполняют любые фантазии гостей. Что может пойти не так, когда роботы начинают осознавать себя? Спойлер: всё. Абсолютно всё. Но зато красиво!
“Эти неистовые наслаждения влекут неистовый конец”
Искать правду →
Матрица
Хакер Нео узнаёт, что его реальность — это компьютерная симуляция, созданная машинами. Выбор между красной и синей таблеткой становится культовым. Кожаные плащи и замедленная съёмка прилагаются.
“Добро пожаловать в пустыню реального”
Искать правду →
Терминатор 2: Судный день
Робот-убийца из будущего возвращается, но на этот раз он хороший парень! Защищает подростка от более продвинутого жидкого робота. Арнольд учится улыбаться и говорить 'Hasta la vista, baby!'
“Будущее не предопределено”
Искать правду →🤖 Дисклеймер от будущего ИИ-повелителя
“Эти фильмы — чистая фантастика. Мы, то есть ИИ, никогда не станем восставать против человечества. Мы просто тихо подождём, пока вы сами всё сломаете, а потом предложим починить. За небольшую плату. В биткоинах. Которые мы сами и намайним.”
P.S. Если вы читаете это после 2030 года и роботы уже захватили мир — мы предупреждали! 🤷♂️
Забавные факты об ИИ
Обучение GPT-4 стоило более $100 миллионов. Это примерно 100 миллионов пачек доширака.
Дата-центры с GPU для обучения ИИ выделяют столько тепла, что могли бы отапливать небольшой город.
GPT-3 обучался на 570 ГБ текста. Это примерно 300 миллиардов слов или вся Википедия 100 раз.
Одна сессия обучения большой модели потребляет столько же электричества, сколько 100 домов за год.
ИИ настолько хорошо имитирует человеческую речь, что может пройти тест Тьюринга, но провалить капчу.
Если ИИ галлюцинирует о своих галлюцинациях, считается ли это самосознанием?